Как тексты попадают в поисковую выдачу Яндекса
Кворум и его влияние на ранжирование документов поисковиком
Документы могут ранжироваться Яндексом не хуже, чем обычные веб-страницы. Но для этого в них не обязательно должны содержаться все слова из поискового запроса. Данное правило касается не только содержимого документа, но и текста ссылки, ведущей на него.
Предлагаем изучить причины того, почему выдача Яндекса изобилует различными документами, в которых отсутствуют слова из вводимых пользователями запросов.
Что такое кворум и как он рассчитывается
Кворум – это достаточная часть совокупного веса слов из запроса, присутствующая в тексте самого документа и (или) линков. Этой части должно хватить для того, чтобы документ попал в SERP поисковой системы и показывался по релевантным запросам.
Для расчета кворума необходимо знать, что он является функцией от пословной длины ключевой фразы и веса слов, которые включаются в него согласно формуле ниже:
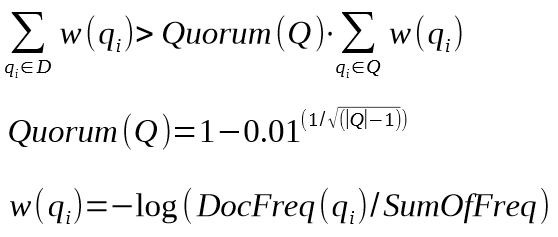
Поисковый запрос помечен буквой Q, функция веса слова обозначена w (q(i)), само слово из запроса – это q (i), а искомый документ соответствует букве D.
Возможно, вы спросите, а что это за переменная 0.01? Такое обозначение получила «мягкость» (она же доля веса кворума). Ее значение может быть и выше, например, 0.06.
Попадание документа в выдачу Яндекса с частью слов из запроса
Сделав некоторые вычисления, мы пришли к выводу, что Яндексу для ранжирования документа не обязательно наличие в нем или его ссылке всех слов из поискового запроса. К примеру, если ключевая фраза состоит из 5 слов, а коэффициент «мягкости» равен 0.06, достаточно, чтобы в документе/тексте его URL содержались 4 слова. Но также стоит понимать, что критерии прохождения кворума зависят от конкретного запроса и количества обнаруженных при его вводе в поисковик документов. А это значит, что данные критерии или правила не статичны и могут претерпевать некоторые изменения.
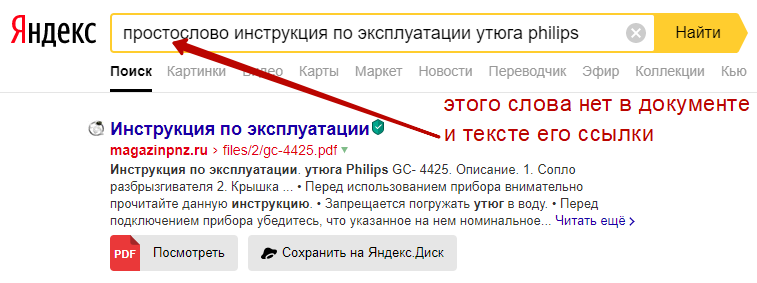
Взгляните на пример выше. По нему видно, что кворум был пройден при нахождении в нем 4 слов из 5 (предлог «по» не в счет). А включение в запрос дополнительного слова никак не повлияло на присутствие данного документа в выдаче. Это доказывает, что для попадания документа в SERP Яндекса достаточно частичного присутствия слов из запроса.
Включение документа в результаты поиска Яндекса с транслитом в URL
Бывает так, что в выдаче поисковика оказывается документ, который вообще не содержит в себе ни одного слова из запроса. Как же он туда попал? Возможно, что он имеет в тексте ссылки транслит одного или нескольких слов из ключевой фразы.
Пример:

Кстати, как вы могли заметить, данный документ не подсвечивается поисковой системой. Это обусловлено тем, что Яндекс не всегда подсвечивает транслит, а выборочно.
Необходимо также подчеркнуть, что наличие транслита в URL документа повышает шансы на прохождение кворума и попадание в SERP.
Ранжирование документа Яндексом с синонимами поискового запроса
Нет прямых вхождений слов из запроса и их транслита в URL, а документ всё равно отображается в выдаче? Скорее всего, текст документа и его ссылки содержат в себе синонимы поискового запроса.
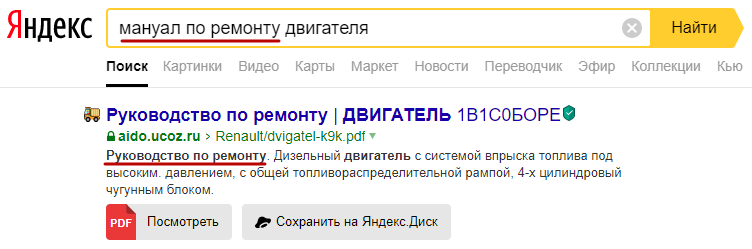
Вот наглядный пример. Ни сам документ, ни его анкор не имеют слово «Мануал», но при этом ранжируется поисковиком. В качестве синонима запроса «Мануал по ремонту двигателя» используется словосочетание «Руководство по ремонту». А слово «Двигатель» встречается в документе далее по тексту.
Влияет ли запросный индекс на включение документа в выдачу
Неопровержимых доказательств этому нет, однако некоторые SEO-специалисты и знатоки поисковых алгоритмов так считают и велика вероятность, что не безосновательно.
Каждый поисковый запрос, который был набран пользователями и привел к переходу на страницу документа, примыкает к совокупности запросов и фиксируется Яндексом. Эта группа запросов получила название «Запросный индекс». Существует мнение, что выдача поисковика может содержать документы, которые находятся благодаря этому индексу. Так это или нет, покажут будущие наблюдения за механизмом поискового ранжирования.

Какие зоны документа не индексируются Яндексом
На данный момент это такие зоны, как:
- Keywords (метатег ключевые слова)
- Description (метатег описание)
- Title картинки (атрибут заголовок)
- Alt картинки (атрибут альтернативное описание)
Пока что поисковик не обращает внимание на данные зоны при поиске документов. Возможно, что со временем ситуация изменится и эти метатеги и атрибуты начнут учитываться краулером. Как говорится: поживем – увидим!
Какие можно сделать выводы о ранжировании документов Яндексом? Чтобы документ попал в SERM, ему не обязательно содержать в себе полностью весь запрос. Достаточно нескольких слов, а порой и обычного транслита в линке или синонимов запроса в тексте.
автор: Александр Долгополов